안녕하세요😊GDGoC Chpater Member 이가현 입니다.
저는 딥러닝 프로젝트에서 학습 과정을 직관적으로 모니터링할 수 있는 도구, TensorBoard의 활용법에 대해 소개해드리려 합니다.
Tensorboard를 먼저 소개 드리고, 딥러닝에서 사용하는 예시, 머신러닝에서 사용할 수 있는 예시를 소개해드리도록 하겠습니다 !
TensorBoard 란?
Tensorflow가 제공하는 학습 과정 시각화 도구로, 학습 중에 발생하는 Loss, Accuracy, Gradient 등의 다양한 로그를
실시간으로 그래프 형태로 확인할 수 있도록 보여줍니다.
학습 지표들을 그래프로 확인 하면서, 학습이 제대로 이루어지고 있는지 확인할 수 있고,
하이퍼파라미터 튜닝 후, 이전 결과와 비교함으로써 효과적인 설정 조합을 탐색하는데 도움을 줍니다.
또, 모델 구조 및 내부 정보를 분석할 수 있어, 파라미터의 분포와 변화, gradient 변화를 추적할 수 있습니다.
또한 연산 그래프를 시각화 함으로써 모델 구조를 파악할 수도 있습니다.
특히, 요즘 이미지, 음성, 텍스트 등 고차원 데이터를 이용한 모델들이 다양하게 개발 되고 있는데요.
Tensorboard에선 고차원 데이터 또한 고차원 임베딩을 통해 데이터 간 관계를 시각화 할 수 있고,
이를 이용한 예측 결과를 기록할 수도 있습니다.

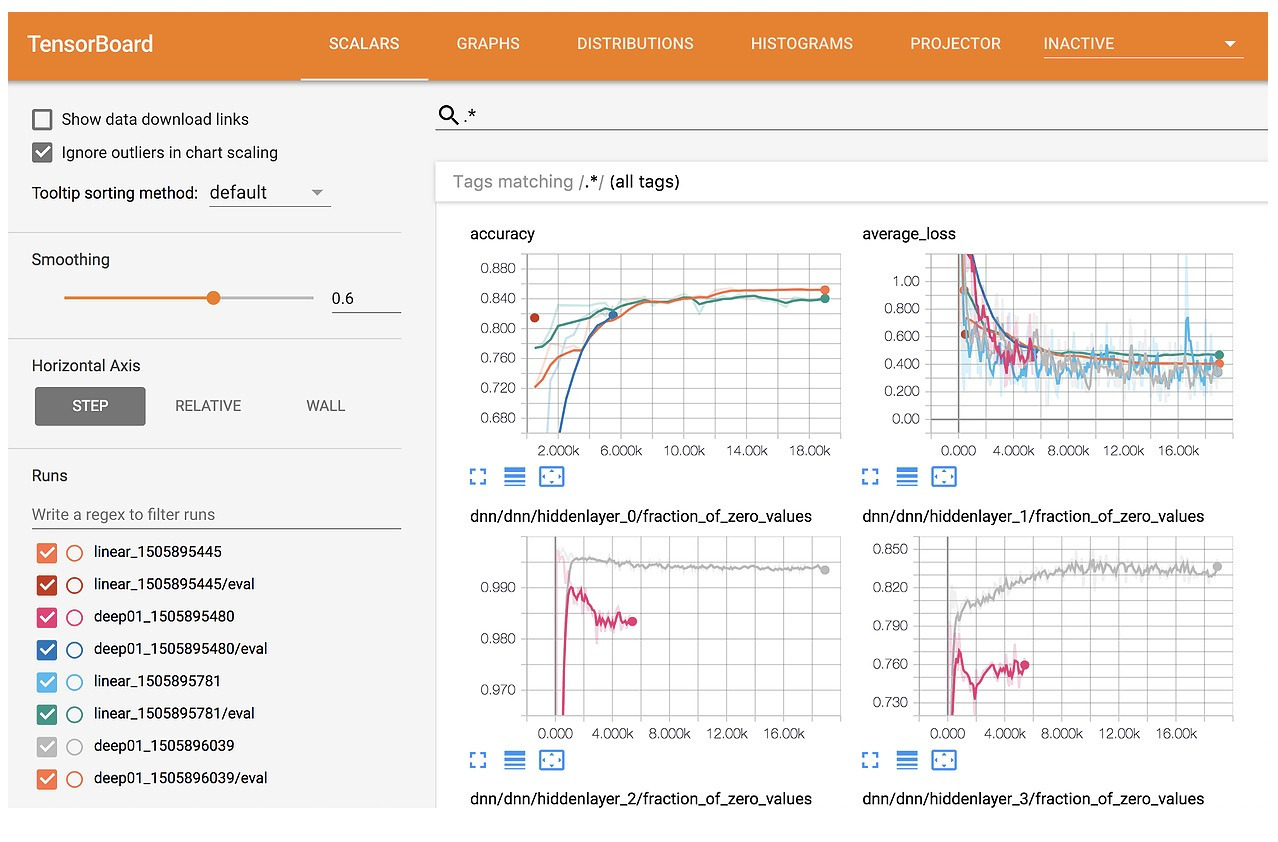
PyTorch와 TensorBoard 연동 실습 - 딥러닝
저는 간단하게 titanic 데이터셋을 불러온 다음 간단한 모델을 정의하여, 실습 진행했습니다.
데이터 셋
X = df.drop("Survived", axis=1).values
y = df["Survived"].values
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
class TitanicDataset(Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.long)
def __len__(self): return len(self.X)
def __getitem__(self, idx): return self.X[idx], self.y[idx]
train_loader = DataLoader(TitanicDataset(X_train, y_train), batch_size=32, shuffle=True)
test_loader = DataLoader(TitanicDataset(X_test, y_test), batch_size=32)
모델 정의
class TitanicNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(6, 16),
nn.ReLU(),
nn.Linear(16, 2)
)
def forward(self, x): return self.net(x)
model = TitanicNet().to(device)
SummaryWriter 설정
: summaryWriter 안에 로그가 저장될 디렉토리 경로를 지정하여, writer을 설정하면 됩니다.
writer = SummaryWriter("runs/nn_titanic")
로그 기록
: 학습 코드 내부에 writer.add_scalar()를 추가하여, 원하는 로그를 기록하도록 설정합니다.
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(100):
model.train()
total_loss = 0
correct = 0
for X_batch, y_batch in train_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
output = model(X_batch)
loss = criterion(output, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
pred = output.argmax(1)
correct += (pred == y_batch).sum().item()
acc = correct / len(train_loader.dataset)
# writer로 로그 기록
writer.add_scalar("Loss/train", total_loss / len(train_loader), epoch)
writer.add_scalar("Accuracy/train", acc, epoch)
Writer close
: 로그 쓰는것을 종료하기 위해 학습이 끝난 후, 아래의 코드를 실행합니다.
writer.close()
Tensorboard 실행
: 로그를 확인할 수 있도록 아래의 코드를 실행하면 됩니다!
%load_ext tensorboard
%tensorboard --logdir=runs
실행하면, 이런식으로 확인할 수 있습니다!

LGBM과 TensorBoard 연동 실습 - 머신러닝
이번 실습에서도 titanic 데이터셋을 불러온 다음 머신러닝의 LightCBM 모델을 사용하여 예측할 수 있도록 진행하였습니다.
머신러닝 모델에서는 학습 로그 기록이 저절로 넘어가진 않지만 로그 기록을 구현하여 동일하게 시각화할 수 있습니다!
데이터 셋
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_test, label=y_test)
SummaryWriter 설정
: summaryWriter 안에 로그가 저장될 디렉토리 경로를 지정하여, writer을 설정하면 됩니다.
writer = SummaryWriter("runs/nn_titanic")
로그 기록을 위한 콜백 함수 정의
def tb_callback(env):
epoch = env.iteration
train_loss = env.evaluation_result_list[0][2]
val_loss = env.evaluation_result_list[1][2]
writer.add_scalar("Loss/train", train_loss, epoch)
writer.add_scalar("Loss/valid", val_loss, epoch)
모델 정의
: 모델 train 코드 안에 콜백 함수를 넣어, 로그 기록을 가능토록 합니다.
## 모델 파라미터
params = {
"objective": "binary",
"metric": "binary_logloss",
"learning_rate": 0.1,
"verbosity": -1
}
model = lgb.train(
params,
train_data,
num_boost_round=100,
valid_sets=[train_data, valid_data],
valid_names=["train", "valid"],
## 콜백
callbacks=[
tb_callback,
lgb.log_evaluation(period=1)
]
)
predict 로그 기록
: 예측한 결과로 나온 로그를 기록하고자 할 때, model.predict 후, 기록하도록 하면, test 결과도 확인 가능합니다!
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, (y_pred >= 0.5).astype(int))
writer.add_scalar("Accuracy/test", acc, 0)
Writer close
: 로그 쓰는것을 종료하기 위해 학습이 끝난 후, 아래의 코드를 실행합니다.
writer.close()
Tensorboard 실행
: 로그를 확인할 수 있도록 아래의 코드를 실행하면 됩니다!
%load_ext tensorboard
%tensorboard --logdir=runs
실행하면, 이런식으로 확인할 수 있습니다!

Tensorboard를 잘 이용한다면 모델의 성능을 빠르게 개선하고,
실험을 반복하면서 정확한 방향으로 나아갈 수 있게 도움을 주는 좋은 도구입니다!
머신러닝 모델을 구현하거나 딥러닝 모델을 구현할 때, 활용하여 좋은 결과를 만들어보세요😎🎶
감사합니다🙌
'GDG on Campus: SSWU 6th > Winter Blog Challenge' 카테고리의 다른 글
| [Winter Blog Challenge] API(Application Programming Interface) (Chapter Member 나향지) (11) | 2025.06.16 |
|---|---|
| [Winter Blog Challenge] OSPF 라우팅 프로토콜 알아보기 (Chapter Member 김아진) (1) | 2025.06.15 |
| [Winter Blog Challenge] (Chapter Member 고원정) (6) | 2025.06.15 |
| [Winter Blog Challenge] Markdown 언어란 무엇인가요? (Chapter Member 이은우) (0) | 2025.06.06 |
| [Winter Blog Challenge] 개발자와 팀을 위한 비밀번호 관리법 (Team Member 나현주) (6) | 2025.06.06 |