오늘은 기본 머신러닝 용어 및 회귀에 대해 알아보려고 합니다 :)
기본 머신러닝 용어
label : 예측할 대상 → 단순 선형회귀에서는 y 변수를 말함
feature : 입력변수 → 단순 선형회귀에서는 x 변수를 말함 → 섬세한 프로젝트일 수록 많은 feture을 가짐
example : data의 특정 예시 → unlabeled, labeled 두 종류로 나누어짐 → 모델을 train하기 위해 사용
model : feature와 label의 관계를 정의
model parameter : 올바른 예측과 결정을 얻기 위해 조정하는 변수들
training : 모델을 만들거나 학습하는 것 = 모델에 labeled된 example들을 제공하고 모델이 feture과 lable 사이 관계를 배우도록 하는 것
inference(추론) : unlabeled된 example들에 train model을 적용하는 것을 의미함 = trained된 모델이 의미 있는 예측값 (y')을 만들도록 하는 것
loss function(손실 함수) : 모델의 질을 평가하는 함수
regression(회귀) : 회귀 모델은 연속적인 값을 예측
classification(분류) : 분류 모델은 이산적인 값을 예측
회귀모델 (regression model)
input 변수를 기반으로 output 변수를 예측하거나 추정하는 방법(회귀 분석)
산술적 예측을 생성하는 모델
regression model 종류
linear regression (선형 회귀) : 두 변수의 관계를 설명하는 선형 함수를 찾아내는 것
logistic regression (로지스틱 회귀) :시스템이 일반적으로 클래스 예측에 매핑하는 0.0에서 1.0 사이의 확률을 생성하는 것
linear regression (선형 회귀)

두 변수의 관계를 설명하는 선형 함수를 찾아내는 것
실제 데이터의 측정값에는 노이즈가 포함될 수 밖에 없다. 이런 노이즈들로부터 다시 원래의 선형 연속함수로 돌아가는 과정이기에 선형 회귀라 한다.
linear model 세우기
모델 → F(m, b; x) = mx + b
모델 파리미터 → m(slope), b(intercept)
모델 파라미터 결정 → 최적화 ↔ 최소제곱법
최소 제곱법 ( least square method)
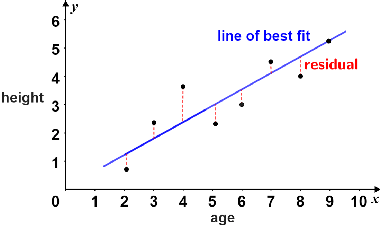
선 또는 곡선에서 잔차(residual)의 제곱의 합을 줄여 데이터 점 집합에 가장 적합한 곡선 또는 가장 적합한 선을 찾는 프로세스
잔차(residual) = 예측 값과 실제 값의 차이
잔차 제곱합 (residual sum of squares = RSS)
n개의 데이터셋
true data points : \( (x_{i},y_{i}^{(true)}), 0 \leq i \leq n-1 \)
expected data points : \( (x_{i},y_{i}^{(true)}), y_{i}^{(pred)} = mx_{i}+b, 0 \leq i \leq n-1\)
잔차(residual) : \( d_{i} = (y_{i}^{(true)} - y_{i}^{(pred)})\)
잔차 제곱합(RSS) : \(\sum_{i=0}^{n-1}d_{i}^{2}\)
선형 회귀 모델의 학습을 통해 모델 파라미터 m, b 값을 조절하여 RSS를 최소화 하고자 함
손실함수를 최소화하는 변수 m, b를 찾아야 하며 이 접근 방식을 최소제곱법이라 한다.
최소 제곱법의 한계
outlier가 많이 존재하는 데이터에서는 최소제곱법을 적용할 수 없다.
dateset의 data point rotn \(\leq\) 1
모든 data point가 같은 \(\x_{i}\) 값을 가지는 경우
선형회귀
\(m^{*}, b^{*}\) 구하기 = 최소제곱추정량 구하기
#x와 y에 대한 m*, b* 구하기
def m(x,y):
numerator = np.sum((x - x_mean) * (y - y_mean))
denominator = np.sum((x - x_mean) ** 2)
return numerator / denominator
def b(x,y):
return y_mean - m * x_mean
'GDG on Campus: SSWU 6th > Winter Blog Challenge' 카테고리의 다른 글
| [Winter Blog Challenge] 로그인 인증 방식 (Chapter Memer 전지연) (0) | 2025.02.24 |
|---|---|
| [Winter Blog Challenge] 검색 증강 생성의 이해 (Chapter Member 박미나) (0) | 2025.02.24 |
| [Winter Blog Challenge] 웹 사이트에서 사용되는 AI 챗봇 (Chapter Member AI/ML 노은서) (0) | 2025.02.24 |
| [Winter Blog Challenge] 개발자를 위한 데이터 전처리 팁 (Chapter Member 한예원) (0) | 2025.02.24 |
| [Winter Blog Challenge] 생성형 AI 종류 알아보기 (Chapter Member 최예인) (0) | 2025.02.24 |