안녕하세요! GDGoC SSWU Chapter Member 정수빈입니다.
저는 요즘 자연어처리(NLP)에 관심이 생겨 공부를 하고 있는데요, 오늘은 제가 공부를 하며 인상깊게 보았던 논문인 “Attention Is All You Need”를 소개하고자 합니다. (https://arxiv.org/abs/1706.03762)
“Attention Is All You Need”는 2017년 구글 브레인(Google Brain)과 토론토 대학교 연구팀이 발표한 논문입니다. 이 논문을 통해 Transformer 모델을 소개하며 딥러닝과 자연어처리 역사에 한 획을 그었다고 볼 수 있습니다.
자연어처리 분야에서는 기계가 사람처럼 문장을 이해하고 생성할 수 있도록 하기 위해 오랜 기간 다양한 모델들을 연구했습니다. 초기에는 RNN(Recurrent Neural Network)과 LSTM(Long Short-Term Memory) 같은 순환 신경망 계열 모델이 등장하며 자연어 이해의 수준을 높였지만, 컴퓨터가 문장을 이해하는 방식에는 큰 문제가 있었습니다.
예를 들자면 사람이 "나는 사과를 먹었다. 그것은 맛있었다."라는 문장을 보았을 때, 그것이 사과를 가리킨다는 걸 자연스럽게 알 수 있지만 기존의 모델들은 문맥을 통해 문장의 뜻을 이해하지 못했습니다.
그 이유는 기존의 자연어처리 모델들이 단어의 순서에 의존하는 방식이었기 때문인데요, RNN 방식은 문장을 한 단어씩 차례대로 읽어야 했습니다.
이것이 문제가 된 이유는
- 문장이 길어질수록 처음 단어를 잊어버렸고,
- 병렬 처리가 어려워서 학습 속도가 느렸습니다.
이러한 한계점을 극복하기 위해 고안된 것이 바로 Transformer 모델입니다.
1. 기존 모델과 Transformer의 차별점
Transformer의 핵심 아이디어는 논문 제목에서 강조한, Self-Attention입니다. .
Self-Attention은 문장 속 모든 단어가 다른 단어들과 어떤 관계를 맺는지 학습하는 방식입니다.
Transformer 기본 구조는 다음과 같습니다.
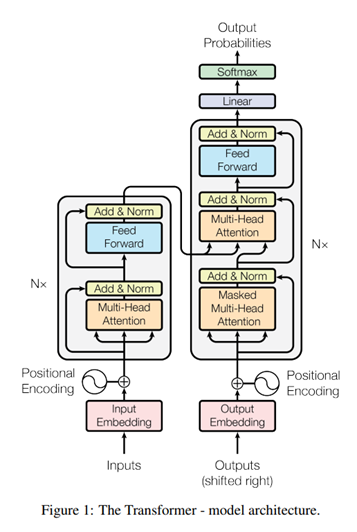
위 그림을 보면 인코더(입력)과 디코더(출력) 부분이 있습니다.
인코더(왼쪽)는 문장을 분석하는 역할, 디코더(오른쪽)는 분석된 정보를 바탕으로 새로운 문장을 만듭니다.
여기서 중요한 게 Attention인데요, Transformer는 Self-Attention을 통해 단어 간의 관계를 자동으로 학습하고 문맥을 더 정확하게 이해할 수 있습니다.
처음 예시로 들었던 문장을 다시 보면, "나는 사과를 먹었다. 그것은 맛있었다."
‘그것’과 ‘사과’의 관계를 Transformer는 스스로 찾아냅니다.
2. Self-Attention
Transformer의 핵심 개념인 Self-Attention에 대해 자세히 알아보고자 합니다.
다음 이미지는 Self-Attention 과정입니다.
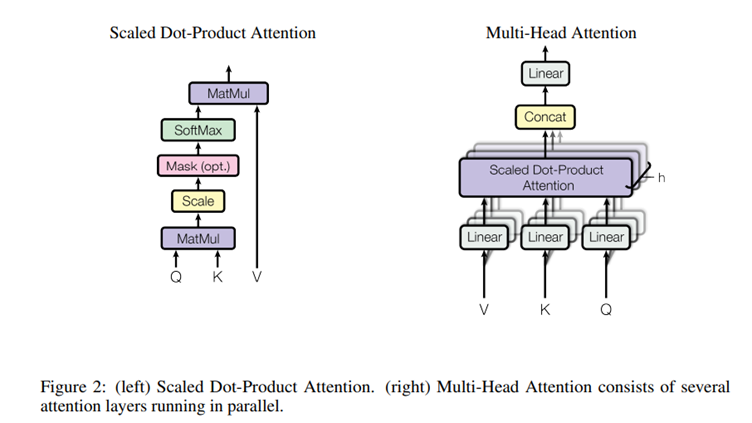
Self-Attention은 문장의 모든 단어가 서로를 참고해서 중요한 단어를 찾는 과정입니다.
1️) 각 단어를 Query, Key, Value로 변환
- 입력 문장의 모든 단어를 Q(Query), K(Key), V(Value) 벡터로 만든다.
- Query(Q): 주어진 단어가 어떤 단어들과 관련이 있는지 찾는 기준
- Key(K): 모든 단어가 각자 제공하는 정보
- Value(V): 최종적으로 Attention을 적용한 후 가져올 정보
2️) 각 단어 간의 연관성 계산(Attention Score 계산)
- Query와 Key를 내적해서 각 단어 간의 Attention Score를 구하고 Softmax 함수를 적용해서 가중치 비율을 조정한다.
- 예를 들면, ‘그것’이라는 단어가 문장 속 어느 단어와 연결될지를 계산하는 것이다.
3️) Value 벡터 조합
- Softmax로 조정된 가중치를 Value 벡터에 곱해서 최종적인 Attention 결과를 만든다.
- 예를 들면, ‘그것’이 ‘사과’를 가리키도록 자동으로 학습하는 것이다.
4️) 멀티-헤드 어텐션(Multi-Head Attention)
- 하나의 Attention만 사용하는 게 아니라 여러 개의 Attention Head를 병렬적으로 사용해서 모델이 다양한 패턴을 학습할 수 있게 한다.
이러한 방식 덕분에 Transformer는 멀리 떨어진 단어들 간의 관계도 잘 학습할 수 있게 되었습니다.
3. Transformer가 NLP를 바꾼 이유
Transformer가 기존 모델들보다 더 강력했던 이유는 다음과 같습니다. 기존 RNN 계열 모델들은 문장을 한 단어씩 읽어야 했지만, Transformer는 모든 단어를 동시에 분석할 수 있어서 더 빠르고 정확했습니다.
정리하자면,
- 병렬 연산 가능 → 학습 속도가 훨씬 빨라짐
- 긴 문장도 효과적으로 처리 → Self-Attention을 통해 멀리 떨어진 단어 관계도 쉽게 학습 가능
- 다양한 NLP 태스크에 적용 가능 → 번역, 요약, 질문 응답, 문서 분류 등 거의 모든 자연어처리 문제에 활용가능
4. Transformer 이후의 NLP 변화
Transformer의 등장 이후로, 이 모델을 기반으로 한 다양한 모델들이 나오기 시작했습니다. 대표적인 모델들과 관련 논문을 소개하겠습니다.
- GPT (2018) (https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf)
GPT는 2018년 OpenAI에서 제시한 언어 모델입니다. GPT는 Transformer의 디코더 아키텍처를 기반으로 Autoregressive 방식으로 다음 단어를 예측하며 언어를 모델링합니다. GPT의 버전과 성능은 계속해서 업데이트 되었고, 생성형 ai의 붐을 일으킨 ChatGPT의 기반 모델입니다.
- BERT (2018) (https://arxiv.org/abs/1810.04805v2)
BERT를 소개한 논문 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” 또한 자연어처리 분야에 큰 영향을 끼쳤습니다. BERT는 2018년 Google에서 제시한 모델로 Transformer의 인코더 아키텍처를 기반으로 하여, 양방향 학습을 통해 문맥 이해력을 높였습니다. 임의로 mask한 단어를 예측하는 방법(MLM), 그리고 두 문장이 연결되는지 예측하는 방법(NSP)으로 언어를 모델링합니다.
5. NLP의 새로운 시대
Transformer는 단순히 좋은 모델이 아니라 기존 NLP 모델의 한계를 극복하고 NLP의 새로운 표준이 되었고, 덕분에 번역, 챗봇, 문서 요약, 검색 엔진 등에서 더 빠르고 정확한 모델을 사용할 수 있게 되었습니다.
지금도 Transformer 기반의 새로운 연구들이 계속 나오고 있고 앞으로는 더욱 더 발전된 AI 모델이 등장할 것으로 예상이 되는데요,
몇 년 뒤에 어떤 AI가 등장할지 궁금해집니다! 사실 그 혁신적인 AI 기술을 선도하는 사람들이 바로 저희일 수도 있겠죠! 앞으로 GDG 멤버분들이 많은 도전을 통해 직접 새로운 AI 시대를 이끌어갈 수 있었으면 좋겠습니다!!
모두 화이팅입니다!